Google Analytics Content Segmentation Via K Means Clustering in R Programming
Ok, so this blog post will be a quite long and will look at how the Google Analytics > Behaviour > All Pages report data can be used to define key website content segments. In trying to do this, I used this link as the main one for Factoextra library usage in R, https://uc-r.github.io/kmeans_clustering [There were several articles on K-Means but I found this link with the cleanest code and easiest to follow], lots of StackOverflow threads in data wrangling part [after the GA API call] and few of Stat Quest videos. I will need to get back to the stat part in a separate blog post. This blog post will cover the overview and what’s doable in R. In a nutshell, there are a few key stages to this segmentation process:
API call via googleAnalyticsR package to pull the data from Google Analytics [by far the easiest part]
Extensive data wrangling [mainly via dplyr] to clean and compress the data
Visualizing distance matrix for variables
Understanding Principle Component Analysis and variability explained
Determining number of clusters using elbow method
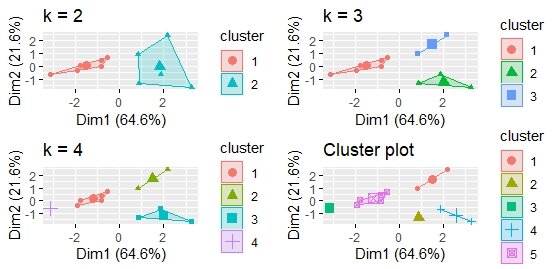
Visualizing the comparative k means clusters side by side
Pulling data from googleAnalyticsR
What’s the above code doing?
You’re loading the main libraries for now. googleAnalyticsR and tidyverse.
Next, you’re using a Google Cloud Platform service key [JSON file] stored on your computer for API calls. This JSON key contains info about the GCP project. Mark Edmondson has a whole tutorial on service key setup and the code has the link to it.
You then check for which view ID’s you want to pull the data from. I have replaced mine with 1234567. You may do so, depending on your authorizations.
Lastly, it’s making a call to Google Analytics to pull the metrics found in the Behaviour report along with page title as the dimension and a time range of 1st Mar 2020 to 16th Feb 2021. Easy, right?
Data Wrangling
Ok, let’s try and visualize the data.

The page titles all overlap with each other. It’s only slightly better if you add the "+ coord_flip() to the command.
Ok, so the data isn’t sorted in descending order [for pageviews] and we can’t read the page titles here. Let’s solve the first one.

Running summary function shows there are some page titles where I had 0 pageviews. Motivating, huh!
d_subset now includes rows where pageviews where greater than zero
Going back the page title being too long, we have now added the row # as a variable “ID”

Ok, we’re making some progress here!
What if I wanted to see a pareto distribution of the contribution to pageviews by individual posts? Here’s one solution below.
It’s first creating a field for running total [cumsum] and then creating a Pareto chart by using the Pageviews field for geom_col and the cumsum field for geom_path component of the plot.

I thought this visualization could’ve been better.

Solution 2 was to using ggQC package where it automatically calculates the percentage contribution towards the total. I thought this was a better visualization. At page ID == 50, I can see that it covers almost 80% of the website content. So, we’ll use the top 50 content for further investigation instead of crowding the analysis with excessive content types. Next, let’s try and classify the content into fewer groups so that it makes the analysis more meaningful.
Ok, a long batch of code…
So, it’s using str_detect function to pretty much run IF/ELSE checks on the page titles and then assign a value in a new column. This new column is called postType. Str_detect is case sensitive. Hence, we first used dplyr to convert the pageTitle values to all lower case and then run str_detect function on all. At the end, I’m excluding Homepage, Others and cumsum field from my new dataset followed by moving postType column to the front of the dataset using the relocate function.
Now that we have the raw data by postType groups, let’s use dplyr to calculate the totals based on postType [we’re aggregating the content types into postType and running functions on this group]
We’re using dplyr above to first, group the data by our new field , postType and then run a series of calculations where weighted bounce rate, avg. time on page, entrance rate, exit rate and page value total are calculated and mutate function then puts these calculations into new columns.

Your content is now compressed and will look like this.
One last bit in data wrangling. The package, factoextra requires the dimension to be a number. So, we’ll use a quick solution to convert postType to a number.
Distance matrix, Principle Component Analysis and K-Means
We’re finally done with the data wrangling part. Next, comes the Distance Matrix part. From here on, the key code I used and tried to understand was from UC’s blog post referenced at the beginning. This uses the factoextra package.

In the above code/visualization, Euclidian distance is being calculated between two data points. I found Analytics Vidhya link the easiest in breaking this down. https://www.analyticsvidhya.com/blog/2020/02/4-types-of-distance-metrics-in-machine-learning/ . In our case, we have certain variables. You’d put that variable on the X axis and the same var on Y axis and then drop the data points for the rows on such a scatterplot. The distance between the two data points comes down to Pythagoras theorem, (x)^2 + (y)^2 as it essentially creates a right triangle along the x axis.

Source: AnalyticsVidhya.com
Therefore, for all the variables, the distance matrix would use the weighted average distances for all variables and you end up with the heatmap to show how content types differ in terms of on-site behaviour.
Creating the k-means chart and Principal Component Analysis in R

Content segmentation where k =2
In the above viz, you can see dim1 (64.6%) and dim2 (21.6%). In a nutshell, it’s reducing the variables to show how much of the variability in the data can be explained by fewer dimensions. I will need to come back to Principal Component Analysis topic in another thread once I have a better understanding of the math. Below is a sample link and code to run for metrics around the PCA.

We now have a few possibilities to increase the number of clusters and check on them. In below code, it’s adding 3/4/5 clusters and then visualizing them side-by-side.

Deciding on number of clusters
The last and final bit of code here looks at the “Elbow” method in agreeing on the number of clusters.

With the cluster centroids [within each cluster], the above chart looks at the aggregated data between individual data points and the centroid clusters and add them up [to check on the variability]. In our case, after 4 clusters, the decrease in sum of squared errors is not significant. Therefore, 4 clusters would be a good idea for content segmentation.
As mentioned in the beginning of the article, the main k means clustering part script was read from here https://uc-r.github.io/kmeans_clustering . I also had to use a lot of StackOverflow in the data wrangling part and I’ve included their links in the code.
The math part for Distance matrix, Principal component analysis, Optimal number of clusters deserves a separate post. I’ll probably use the same dataset from my blog to try and explain. The idea for this one was to use R from start to finish without going with the temptation of cleaning the data in Excel. It took some time but I feel it was worth it. I couldn’t find too many blog posts on using this technique on website data and thought of doing this.
Full script below. Link to github page: https://github.com/madilk/google-analytics-content-segmentation-k-means-clustering
Follow up post on how scale function works in R programming with example.



