
BigQuery ML: Time Series Forecasting Using Google Analytics App+Web Data
Ok, this post is mainly me using the Google Cloud documentation to work this out step-by-step in BigQuery. If you’re here, I presume that you already have a Google App+Web property in Google Analytics and are sending data to BigQuery. BigQuery integration with GA App+Web is huge step up for Google Analytics and can only lead to good things in the future.
The source documentation I’ve used here is from Google Cloud. While there is a Google Analytics public dataset, it’s always better to run it across your own data + get familiar with GA App+Web data in BigQuery.
Let’s jump in and see how the data is structured in BigQuery. As it is hit based, there’s no sampling issues that you’d face in Standard reporting or GA V4 Reporting API.
#standardSQL SELECT * FROM `analyticslog-app-plus-web.analytics_240627631.events_20200731` LIMIT 1
In the above query, we’re requesting for BQ to select all rows from the data table and limit it to 1 result in the console (Results tab). Data in BigQuery from GA App+Web is sent as a partitioned table with daily events being in events_YYYYMMDD tables, which is why I put the 20200731 in the query. I’ll come able to this point in a bit.

GA App+Web is built around users rather than sessions. It does have engagedsessions as a metric, which would be the opposite of a bounced session but will go into that in another post. Let’s say we want to forecast number of users to expect. As there is no user_id field provided to GA, it used the user_pseudo_id field, which in this case is the browser client ID field. So, we’ll use this field in our forecasting.
Coming back to the partitioned tables part with YYYYMMDD tables, you will obviously want to forecast something beyond a day - which is where you need more data. To bypass this, you’ll need to use the Wildcard operator to run a query across multiple tables. [I got this solution from one of the comments in Simo Ahava’s post on BigQuery]. You also have the option of using TABLE_SUFFIX to run this for a particular digit. In our example, let’s go with * as I only have data from 23rd Jul 2020. So, here’s the query run across all dates since launch.
#standardSQL SELECT PARSE_TIMESTAMP("%Y%m%d", event_date) AS parsed_date, COUNT(DISTINCT user_pseudo_id) AS users, FROM `analyticslog-app-plus-web.analytics_240627631.events_*` GROUP BY event_date, user_pseudo_id
What’s happening in the above query?
We are selecting event_date and user_pseudo_id from the table, converting the event_date YYYYMMDD into a time series format date, counting the distinct number of user_pseudo_id’s in the table and calling them Users. The wildcard operator at the end is .events_* - which means run across all dates. Hit Run. You can see that the field parsed_date is now in a proper time series date format that can be used. Click on Explore dat to open this in Data Studio.

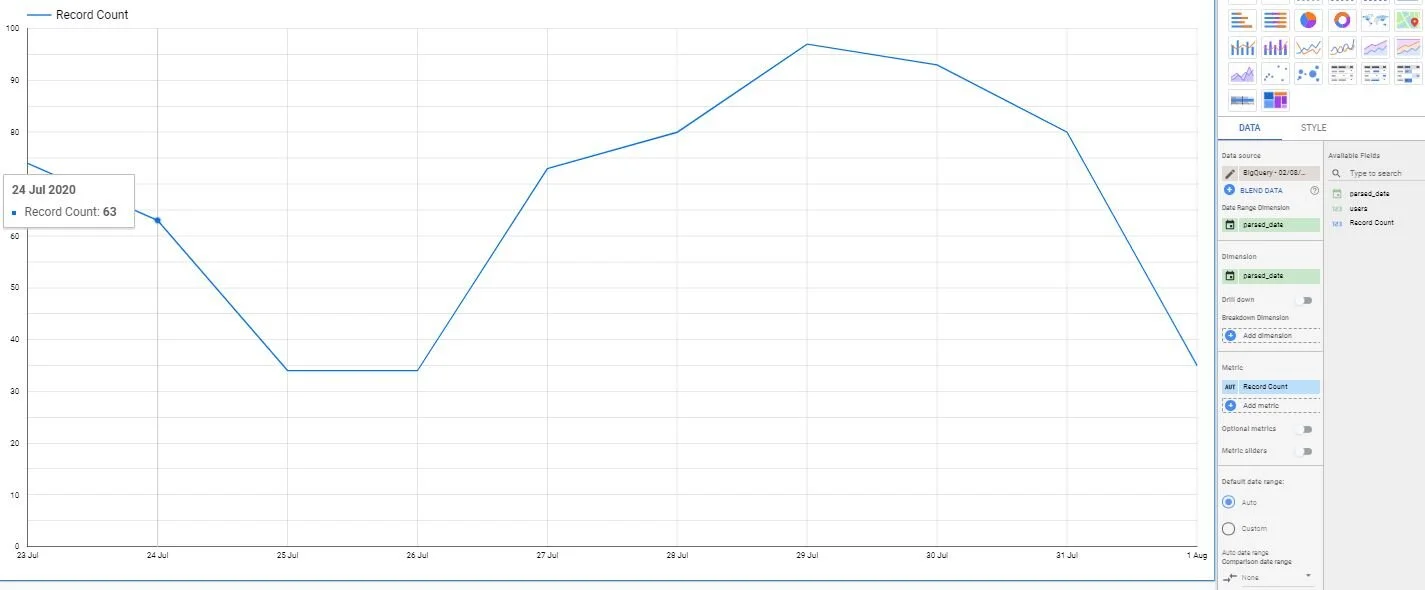
This would be a good check-in point to compare the chart with some Users values in GA reporting interface to ensure that they match , meaning you got the query right!
From here on, The Google Cloud source documentation can be used as is to go through the next steps of creating the model, checking model accuracy and finally forecasting it in BigQuery + pushing it to Data Studio.
#standardSQL CREATE MODEL bqml_tutorial.ga_arima_model OPTIONS (model_type = 'ARIMA', time_series_timestamp_col = 'parsed_date', time_series_data_col = 'users' ) AS SELECT PARSE_TIMESTAMP("%Y%m%d", event_date) AS parsed_date, COUNT(DISTINCT user_pseudo_id) AS users, FROM `analyticslog-app-plus-web.analytics_240627631.events_*` GROUP BY event_date, user_pseudo_id
There are loads of options within the ARIMA model part of the query and cloud documentation covers it in detail. As it’s a simple time series, parsed_date is the time here while Users metric is the value that we’d like to forecast. Running the query should create the model in the left pane navigation.

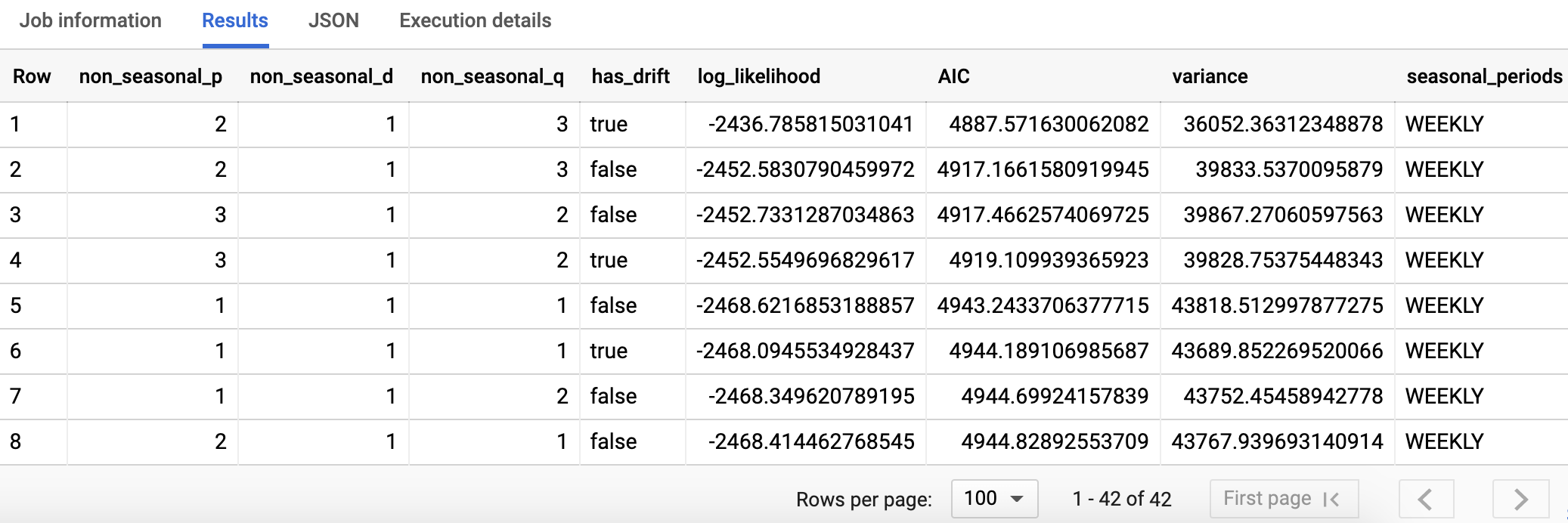
Evaluate the model: Let’s evaluate what information we have on the model knowing that we only have data from 23rd Jul 2020.
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.ga_arima_model`)

How the model evaluation looked for my data.
How it should look.
Seasonal_periods field could not detect the seasonality. From the TS documentation: seasonal_periods is about the seasonal pattern inside the input time series. It has nothing to do with the ARIMA modeling, therefore it has the same value across all output rows. It reports a weekly patten, which is within our expectation as described in step two above.
AFAIK, Arima model needs a lot more data points to evaluate full seasonality. Hmm, that got me looking over at the BigQuery documentation for BigQuery ML models to see if there was a way to run the model more efficiently. https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-create-time-series
Reading this documentation, there is an option for DATA_FREQUENCY [The default being AUTO_FREQUENCY]. Would adding this bit of information help the model??
#standardSQL #updated model name as V2 and added DATA_FREQUENCY param CREATE MODEL bqml_tutorial.ga_arima_model_v2 OPTIONS (model_type = 'ARIMA', time_series_timestamp_col = 'parsed_date', time_series_data_col = 'users', DATA_FREQUENCY= 'DAILY' ) AS SELECT PARSE_TIMESTAMP("%Y%m%d", event_date) AS parsed_date, COUNT(DISTINCT user_pseudo_id) AS users, FROM `analyticslog-app-plus-web.analytics_240627631.events_*` GROUP BY event_date, user_pseudo_id
No luck. It still cannot identify seasonality [which makes sense…]. You might face this issue as well if your data is pretty new with almost no seasonal cycles in the data. To continue with the example, I’ll create a dummy data set with tiemstamp and user values to check the full setup in BigQuery.
Here’s how the dummy dataset is in Excel. It’s a daily summary of users with the below formula. IF it’s the first day of the month, then generate a random number between 1200 to 2500, ELSE take the previous cell and add 10% to it. Since this new sample data has user counts by day and not hit data by user id, the query is now running a SUM(pseudo_user_id_count) AS history_value instead of a COUNT(DISTINCT).

Go ahead and create a new dataset for this CSV import and create a new table for this daily data.

If you now try running the query with all the Forecasting steps given in the Google Cloud documentation, it will work. The only challenge I faced was that the historical data had a timestamp of YYYY-MM-DD while the forecast_timestamp had a timestamp of YYYY-MM-DD HH:MM:SS UTC, which breaks the model when you try putting them together.

hmmm…
To diagnose this, I first selected the historical data part of the query and ran it, it worked. I then ran the forecast model part separately, it also ran. Ok…Observing the timestamp details in both sub queries lead to me Stackoverflow for a solution. https://stackoverflow.com/questions/63217923/bigquery-how-can-i-add-000000-utc-to-an-existing-timestamp/63218938#63218938
In the full below, I now have an operation TIMESTAMP(event_date) as history_timestamp2 which is what will be used in plotting the timeseries [along with forecast_timestamp in the second half of the query].
#standardSQL #https://cloud.google.com/bigquery-ml/docs/arima-single-time-series-forecasting-tutorial SELECT history_timestamp2 AS timestamp, history_value, NULL AS forecast_value, NULL AS prediction_interval_lower_bound, NULL AS prediction_interval_upper_bound FROM ( SELECT TIMESTAMP(event_date) as history_timestamp2, event_date AS history_timestamp, SUM(pseudo_user_id_count) AS history_value, FROM `analyticslog-app-plus-web.excelSampleData.sampleExcelData` GROUP BY event_date ORDER BY event_date ASC ) #https://stackoverflow.com/questions/63217923/bigquery-how-can-i-add-000000-utc-to-an-existing-timestamp/63218938#63218938 UNION ALL SELECT forecast_timestamp AS timestamp, NULL AS history_value, forecast_value, prediction_interval_lower_bound, prediction_interval_upper_bound FROM ML.FORECAST(MODEL bqml_tutorial.ga_arima_model_v4, STRUCT(30 AS horizon, 0.8 AS confidence_level))
Congrats! The query ran and you’re now ready to plot the data. Head over to DS and put in the history_value, forecast_value, upper and lower prediction intervals [set at 80% in the query].

This post doesn’t go into the stats element of the ARIMA model. This is something that I’ll be diving into as I try to improve my stats knowledge.
Overall, I would highly recommend that everyone have a parallel implementation for GA App+Web beta and use BigQuery to check out the possibilities. The GA public dataset is always available but it’s more fun when you do this with your own data and learn something new along the way.




