Entity and Sentiment Analysis On Website Survey Text Data Using Google Cloud Natural Language API
The more I use Google Cloud Platform, the more I’m fascinated with the possibilities. One of the listed APIs is the Natural Language API which uses Natural Language Processing to detect entities and sentiment. This is exactly what’s used in social listening tools across. This got me curious on how to use it in the context of digital analytics where websites often have survey questions with open ended questions. This is a very good practice as it help understand the why behind a particular rating/review. This will be a rather long post in trying to recreate the example from Alicia Williams from Google Cloud Next video [GCP page on same: https://cloud.google.com/blog/products/gcp/analyzing-text-in-a-google-sheet-using-cloud-natural-language-api-and-apps-script ] and has links to several pages that I used for help, some intro level explanations.
If you head over to the Natural Language API demo https://cloud.google.com/natural-language and try pasting a text, you’ll get a sense of how this works. Example survey response: “Definitely a good offer for short term staying. The Host was very friendly, helpful and always reacted very fast and dependable. The Studio is only a few steps away from the T-Line which makes it easy to explore the city. There's no room for unpacking stuff from the suitcase that's why it's better for short term stays.”

Entities focuses on Nouns - Proper and personal nouns, which helps detect what is being discussed.
![Sentiment tab helps understand the emotion behind the entire document and individual sentences that make up the document. Scores can be between -1 and 1 [negative to neutral to positive] while magnitude tells the level of emotion behind the sentimen…](https://images.squarespace-cdn.com/content/v1/5640e86be4b031347f7c7b81/1598113973189-JWPLTAJEVJLHVCW3U4I0/google+cloud+natural+language+api+demo+sentiment.JPG)
Sentiment tab helps understand the emotion behind the entire document and individual sentences that make up the document. Scores can be between -1 and 1 [negative to neutral to positive] while magnitude tells the level of emotion behind the sentiment. Higher magnitude = more emotional. More on this later.
Ok, so the video from Alicia Williams uses a Kaggle dataset for an AirBnb property, containing the reviews (text). Link to Kaggle dataset: https://www.kaggle.com/airbnb/boston .
Once your data is in a Google Sheet with this type of syntax, https://docs.google.com/spreadsheets/d/1KKkjqDtnRJMADNgHtHk5aC-uxLauNCkWgqybfdlG-ac/edit#gid=70832977 it does a few things. First, it detects the language used for the review [using DETECTLANGUAGE formula] and IF NOT in English, it then uses GOOGLETRANSLATE formula to convert the review into English. This is required because Entity + Sentiment analysis [at the same time] is only available in English, Japanese and Spanish [at the time of this writing, as per https://cloud.google.com/natural-language/docs/languages ]
![You can now paste all the reviews for this particular AirBnb listing [66288]. Total reviews should be 404.](https://images.squarespace-cdn.com/content/v1/5640e86be4b031347f7c7b81/1598114251098-315JPQSLRP3P40PKVHTF/google+cloud+natural+language+api+sample+review+in+google+sheets.JPG)
You can now paste all the reviews for this particular AirBnb listing [66288]. Total reviews should be 404.
The last column is entity_sentiment, which will be auto-populated by the Google Apps script.
The script works in the following way: It checks the comment_english column, extracts the entities and sentiment and spits it out into a new sheet called entitySentiment. Once it’s done for a particular block of text, it will mark entity_sentiment column call as “complete”. This helps in avoiding running the analysis on previously available data.
I would suggest that you used the Github page for this as the original GCP blog post link has a leading quote missing in the code, causing it to break. https://gist.github.com/aliciawilliams/2f27bb592d16109c8c977dab5302af13

Note: Before you run the script, disable Chrome V8 in Apps Scripts. Otherwise, you’ll get an error on line 74.
//you'll need to generate an API key from GCP to run this. function retrieveEntitySentiment (line) { var apiKey = "your key here"; var apiEndpoint = 'https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=' + apiKey;
For this project in GCP, you’ll need to first enable the Natural Language API and then generate an API key that you can paste within the Google Sheet Apps script.
The Google Apps script’s key functions are in the natural language functions markEntitySentiment [fo each row] and retrieveEntitySentiment.
Once you execute the script on your document, you’ll see two changes in the Google sheet.
First, the entity_sentiment column will begin to show as “complete” as it works its way through each document.


Second, in a separate sheet, you’ll see the entities and sentiment for each entity [with the ID column referencing back to an individual review].
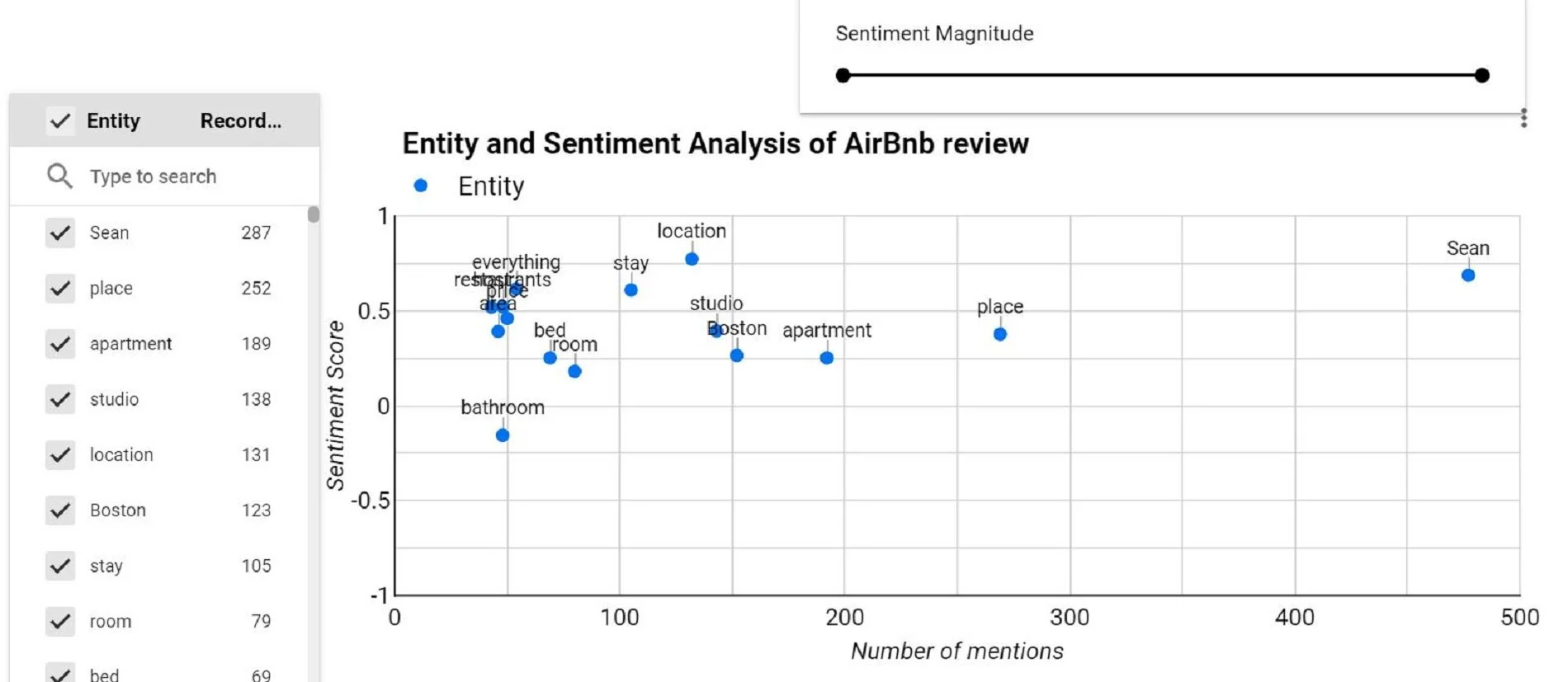
Once this is done, the heavy lifting has already been done. You can now connect it to a Data Studio scatter plot to know the frequency with with particular entities are being talked about along with the sentiment score behind them.

There’s obviously so many different ways in which the data can be presented but as a start, we can see from the plot that Sean [most probably, the host] has the maximum number of mentions [as expected] but what’s worth noting is that his sentiment score is at 0.7 [maximum possibility of 1], which is great! At the other extreme end, the bathrooms have a lower than zero score. Some sample mentions containing text about ‘bathrooms’.
Bathroom was ok, bed comfortable in a quiet neighbourhood.
What I didn't like was the smell of the room and bathroom's poor maintenance.
The bathroom is a bit older, so be prepared for some wear-and-tear.
Not bad, huh!
Reading such reviews in detail might be worth the time and / or improving bathroom facilities to enhance user guests’ experience would be the next step in this.
More detailed explanations:
I found this particular site very helpful in explaining the NLP concepts + pricing part of Natural Language API. https://www.toptal.com/machine-learning/google-nlp-tutorial

As you move through the example input sentences, you notice how the magnitude changes between them [to explain the intensity of the emotion]

When you compare the differences between the three options for NL API, AutoML and Custom models, the easiest one to start out with is the NL API. However, it’s also the least flexible.
Full code for Google Apps script, taken from Alicia William’s Github page.




